Guide to Sharding and Partitioning in Relational Databases

Introduction
As databases grow in size and complexity, managing and querying large volumes of data becomes more challenging. Two popular techniques to address these challenges are partitioning and sharding. Both methods involve breaking down data into smaller, more manageable pieces, but they differ in their approach and use cases. This blog post will explore the concepts of partitioning and sharding, their similarities and differences, and when to use each technique.
What is Partitioning?
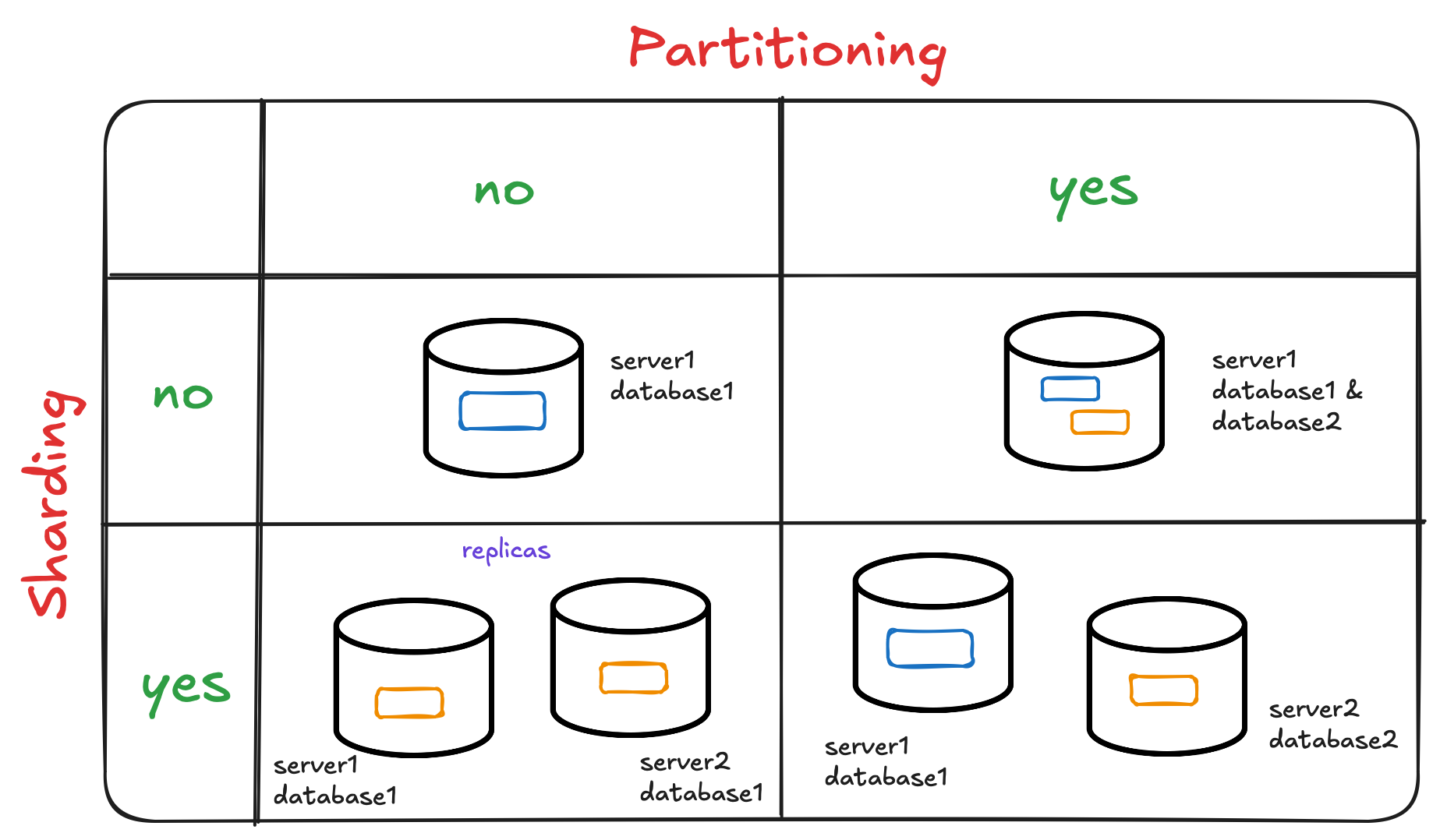
Partitioning is a database design technique that divides a table into smaller, more manageable parts called partitions. Each partition is a subset of the data within a single database instance, based on specific criteria such as value ranges, lists of values, or hash functions.
Let's consider an e-commerce database with a large dataset. One can apply different partitioning strategies to this table:
Range Partitioning by Date: Partition the orders table by date ranges, which is useful for managing historical data and improving query performance for date-based queries.
List Partitioning by Region: If the e-commerce platform operates in different regions, it can be partitioned by the customers table by region for better data locality.
What is Sharding?
Sharding is a database architecture technique that involves distributing data across multiple separate database servers, each called a shard. Each shard is an independent database instance, and collectively, the shards make up a single logical database.
For the same global e-commerce platform, it might make sense to shard data based on geographic regions to improve latency for users in different parts of the world.
North America Shard:
- customers (in NA)
- orders (from NA)
- inventory (in NA warehouses)
Europe Shard:
- customers (in Europe)
- orders (from Europe)
- inventory (in European warehouses)
Asia Shard:
- customers (in Asia)
- orders (from Asia)
- inventory (in Asian warehouses)
Partitioning vs Sharding: A Comparison
| Aspect | Partitioning | Sharding |
| Definition | Dividing a table into smaller parts within a single database instance | Distributing data across multiple independent database servers |
| Data Location | Same database server | Multiple database servers |
| Transparency | Usually transparent to the application | May require application-level changes |
| Complexity | Generally simpler to implement | More complex, requires careful design |
| Scalability | Vertical scalability (scale-up) | Horizontal scalability (scale-out) |
| Query Distribution | Handled by the database management system | May require a routing layer in the application |
| Data Consistency | Easier to maintain | More challenging due to distributed nature |
| Use Case | Large tables within a single database | Extremely large datasets that exceed single server capacity |
Referenced from Arpit Bhayani Youtube
Why do we need Partitioning and Sharding?
Both partitioning and sharding are techniques used to address the challenges that come with managing and querying large volumes of data:
Improved Performance: By breaking data into smaller chunks, queries can be executed faster, and parallel processing becomes more efficient.
Enhanced Scalability: As data grows, it becomes easier to add new partitions or shards to accommodate the increased volume.
Better Manageability: Smaller data sets are easier to manage, backup, and maintain.
Increased Availability: In the case of sharding, if one shard goes down, the others can still operate, providing better fault tolerance.
When to Choose Partitioning or Sharding
The choice between partitioning and sharding depends on various factors:
Choose Partitioning when:
Data fits on a single server but query performance is slow
Need to manage data lifecycle (e.g., archiving old data)
Want to improve manageability without changing the application code
Choose Sharding when:
Data volume exceeds the capacity of a single server
Need horizontal scalability to handle high traffic
Require high availability and fault tolerance
Implementation Considerations
When implementing partitioning or sharding, consider the following:
Choose the right partitioning/sharding key: This is crucial for even data distribution and good query performance.
Handle data growth: Plan for adding new partitions or shards as the data increases.
Manage cross-partition or cross-shard operations: These can be challenging and may need special handling as discussed later
Ensure data consistency: This is especially important for sharded databases.
Monitor performance: Regularly check for hot spots or uneven data distribution.
Plan for maintenance: Think about plans to handle schema changes, backups, and data recovery.
Can Partitioning and Sharding Work Together?
Yes, partitioning and sharding can be used together. In fact, it's common to implement both strategies in large-scale systems but on when all other scalability options have been exhausted.
First, shard the data across multiple servers based on a high-level criterion (e.g., geographic location).
Then, within each shard, partition the data further based on more specific criteria (e.g., date ranges).
This combined approach allows for both horizontal scalability and efficient data management within each shard.
Advantages and Disadvantages
Partitioning
Advantages
Improved query performance: Queries can run faster as they only need to scan relevant partitions.
Easier data lifecycle management: Old data can be easily archived or deleted by removing entire partitions.
Better manageability of large tables: Maintenance operations can be performed on individual partitions, reducing downtime.
Disadvantages
Limited by the capacity of a single server: While partitioning helps manage large tables, it's still constrained by the resources of a single machine.
Potential for uneven data distribution: Poor partitioning strategies can lead to skewed data distribution, affecting performance.
Complexity in partition maintenance: Adding or removing partitions, especially in live systems, can be challenging.
Sharding
Advantages
Horizontal scalability: You can add more shards to accommodate growing data and traffic.
Improved performance for large datasets: Data is distributed across multiple servers, allowing for parallel processing.
Better fault tolerance and availability: If one shard goes down, others can still operate.
Disadvantages
Increased complexity in application design: Applications need to be shard-aware and handle data routing.
Potential for data inconsistency: Maintaining consistency across shards can be challenging, especially for transactions spanning multiple shards.
Challenges in performing cross-shard operations: Joins and transactions across shards are complex and can be performance-intensive.
Sharding: Impact on Queries
Sharding typically requires more significant changes to query patterns:
Shard Determination: The application needs to determine which shard contains the required data.
Query Routing: Queries must be sent to the appropriate shard(s).
Result Aggregation: For queries spanning multiple shards, results need to be combined.
The Cost of Cross-Shard Joins
Cross-shard joins involve combining data from multiple shards. These operations can be very costly in terms of performance and resources, and are often seen as a bad practice in sharded database architectures. Here's why:
Network Overhead: Data from multiple shards needs to be transferred over the network to a single location for joining, which can be slow and bandwidth-intensive.
Increased Latency: The time required to collect data from multiple shards and perform the join operation can significantly increase query response times.
Resource Intensiveness: Cross-shard joins require more CPU and memory resources to process and combine large datasets from different shards.
Scalability Limitations: As the number of shards increases, the performance of cross-shard joins degrades rapidly, limiting the scalability benefits of sharding.
Complexity: Implementing and managing cross-shard joins adds considerable complexity to both the database layer and the application logic.
Strategies to Solve Cross-Shard Join Problems
While it's best to design the schema and application to avoid cross-shard joins, here are several strategies to handle situations where they seem necessary:
Denormalization
Strategy: Duplicate some data across shards to avoid the need for joins.
Example: Store a user's basic information in both the 'users' shard and the 'orders' shard.
Trade-off: Increased storage usage and potential data consistency issues.
Application-Level Joins
- Strategy: Perform the join operation in the application code rather than in the database.
Scatter-Gather Queries
- Strategy: Query all relevant shards independently and combine the results in the application.
Pre-Join Tables
Strategy: Create pre-joined tables that are updated periodically or in real-time.
Example: Create a 'user_order_summary' table that combines user and order data, updated through a background process.
Trade-off: Increased storage usage and potential for slightly outdated data.
Hybrid Approach
Strategy: Use a combination of sharding for most data and a centralized database for frequently joined data.
Example: Shard customer orders but keep a centralized customer profile database.
Trade-off: Increased system complexity and potential for inconsistencies.
Data Duplication with Eventual Consistency
Strategy: Duplicate necessary data across shards and use asynchronous updates to maintain eventual consistency.
Example: Store a copy of user profile data in each shard where the user has activity, and update it asynchronously when the main profile changes.
Trade-off: Increased storage usage and handling of potential temporary inconsistencies.
Distributed SQL Engine
Strategy: Employ a distributed SQL query engine that can efficiently handle cross-shard joins.
Example: Use technologies like Presto, Apache Drill, or CockroachDB that are designed to query across distributed data sources.
Trade-off: Added complexity in setup and maintenance of an additional system component.
Implementing Cross-Shard Join Solutions
When implementing solutions to avoid cross-shard joins, consider the following:
Analyze Query Patterns: Understand the most common and important queries to guide the data distribution and duplication strategies.
Balance Data Consistency and Performance: Choose strategies that balance data consistency and query performance for the specific needs.
Monitor and Optimize: Regularly check query performance and data distribution, and adjust the strategies as the data and usage patterns change.
Consider Data Volume and Growth: Design the solution to handle future data growth and changing access patterns.
Leverage Caching: Use caching strategies to reduce the need for frequent cross-shard data access.
Conclusion
Both partitioning and sharding are powerful techniques for managing large-scale databases. Partitioning offers a simpler way to improve performance and manageability within a single database instance, while sharding provides a path to virtually unlimited scalability across multiple servers.
The choice between partitioning and sharding (or using both) depends on your specific needs, including data volume, scalability requirements, and application complexity. By understanding the strengths and limitations of each approach, you can make informed decisions to optimize your database architecture for performance, scalability, and manageability.



